This post is on the work I presented at DH ’09, plus some thoughts on what’s next for my project. It’s related to this earlier post on preliminary part-of-speech frequencies across the entire MONK corpus, but includes new material and figures based on some data pruning and collection as mentioned in this post (details below).
A word, first, on why I’m working on this. I don’t really care, of course, about the relative frequencies of various parts of speech across time, any more than chemists care about, say, the absorption spectra of molecules. What I’m looking for are useful diagnostics of things that I do care about but that are hard to measure directly (like, say, changes in the use of allegory across historical time or, more broadly, in rhetorical cues of literary periodization).
My hypothesis is that allegory should be more prominent and widespread in the short intervals between literary-historical periods than during the periods themselves. Since we also suspect that allegorical writing should be “simpler” on its face than non-allegorical writing (because it needs to sustain an already complicated set of rhetorical mappings over large parts of its narrative), it makes sense (in the absence of a direct measure of “allegoricalness”) to look for markers of comparative narrative simplicity/complexity as proxies for allegory itself. I think part-of-speech frequency might be one such measure. In any case if I’m right about allegory and periodization and if I’m also right about specific POS frequencies as indicators of allegory, then we should expect certain POS frequencies to exhibit significant (in the statistical sense) fluctuations around periodizing moments and events. (I wish there were fewer ifs in that last sentence; I’ll say a bit below about how one could eliminate them.)
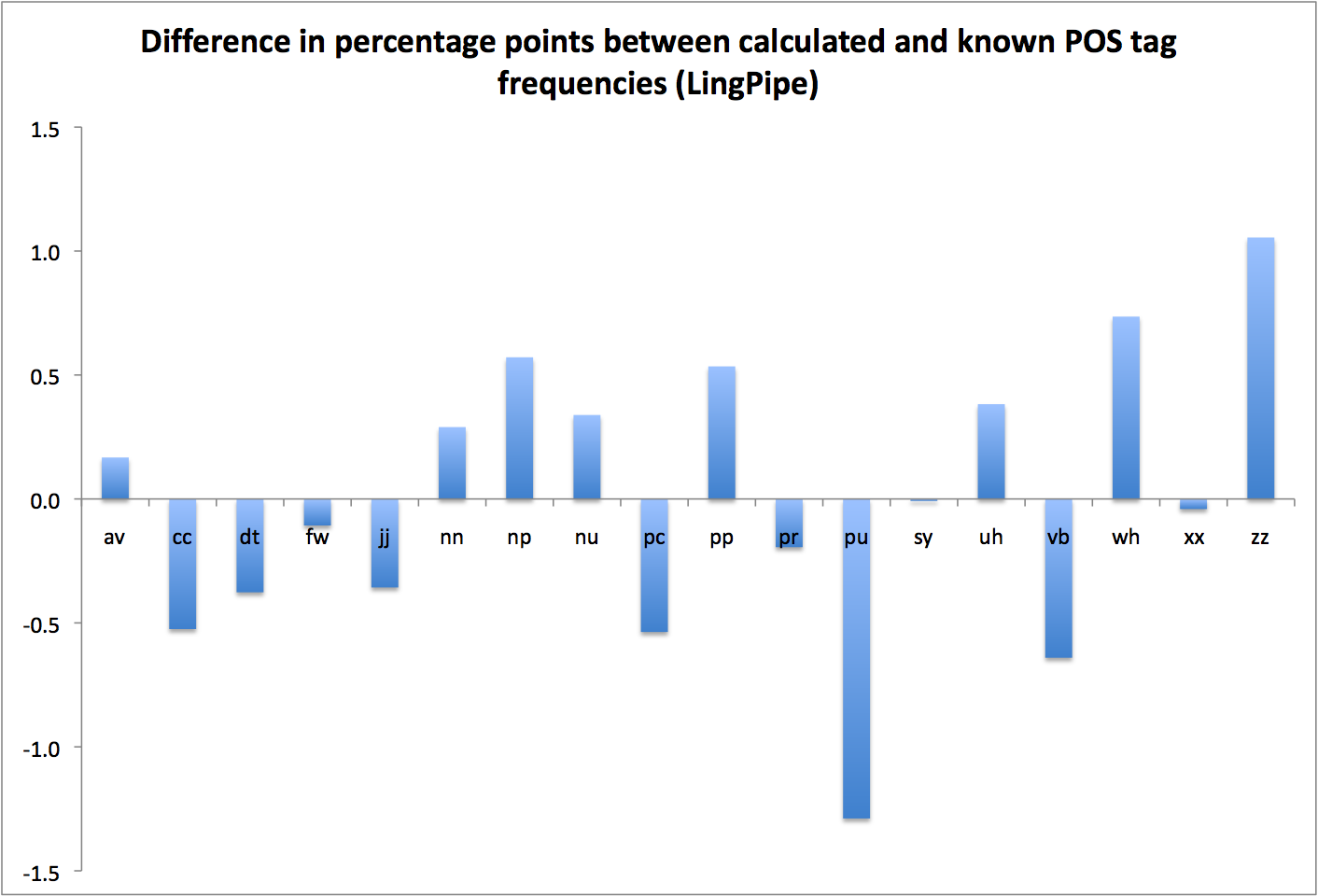
So … what do we see in the MONK case? Recall that the results from the full dataset looked like this:

POS Frequencies, Full MONK Corpus
But that’s messy and not of much use. It doesn’t focus on the few POS types that I think might be relevant (nouns, verbs, adjectives, adverbs); it includes a bunch of texts that aren’t narrative fiction (drama, sermons, etc.); and it’s especially noisy because I didn’t make any attempt to control for years in which very few texts (or authors) were published. (Note that the POS types listed are the reduced set of so-called “word classes” from NUPOS.)
Here’s what we get if we limit the POSs (PsOS?) in question, exclude texts that aren’t narrative fiction, and group together the counts from nearby years with low quantities of text:

POS Frequencies, Reduced and Consolidated MONK Corpus
And here’s the same figure with the descriptive types (adjectives and adverbs) added together:

POS Frequencies, Reduced and Consolidated MONK Corpus (Adj + Adv)
[Some data details, skippable if you don’t care. First, note that the x axes in all three figures need to be fixed up; they’re just bins by year label, rather than proper independent variables. I’ll fix this soon, but it doesn’t make much difference in the results. You can download the raw POS counts for the full corpus (not sorted by year of publication), as well as those restricted to texts with genre = fiction. These are interesting, I guess, but more useful are the same figures split out by year of publication, both for the whole corpus, and just for fiction (presented as frequencies rather than counts). Finally, there are the fiction-only, year-consolidated numbers (back to counts for these, because I’m lazy). The table of translations between the full NUPOS tags and the (very reduced) word classes presented here is also available.]
So what does this all mean? The first thing to notice is that there’s no straightforward confirmation of my hypotheses in these figures. There’s some meaningful fluctuation in noun and verb frequency over the first half of the nineteenth century—which I think might be an interesting indication of the kind of writing that was dominant at the time (see the noun and verb frequency section of this post)—but no corresponding movement in the combined frequency of adjectives and adverbs. This might mean several things: I might be wrong about the correlation between such frequencies and periodizing events, or I might not be looking at the right POS types, or (quite likely, regardless of other factors) I might not have low enough noise levels to distinguish what one would expect to be fairly small variations in POS frequency.
Where to go from here? A few directions:
I’ll keep working on a bigger corpus. The fiction holdings from MONK are only about 1000 novels, spread (unevenly) over 120+ (or 150+) years. So we’re looking at eight or fewer books on average in any one year, and that’s just not very much if we want good statistics.
There are a couple of ways to go about doing this. Gutenberg has around 10,000 works of fiction in English, so it’s an order of magnitude larger. There are issues with their cataloging and bibliographic quality, but I think they’re addressable and I’m at work on them now. The Open Content Alliance has hundreds of thousands of high-quality digitizations from research libraries, though there are some cataloging issues and I’m not sure about final text quality (which relies on straight OCR rather than hand-correction as does Gutenberg). Still, OCA (or Google Books, depending on what happens with the proposed settlement, or Hathi) would offer the largest possible corpus for the foreseeable future. I’ve been talking to Tim Cole at UIUC about the OCA holdings and will report more as things come together.
But I think it’s also worth asking whether or not POS frequencies are the right way to go; I started down that path on a hunch, and it would be nice to have some promising data before I put too much more effort into pursuing it. What I need, really, are some exploratory descriptive statistics comparing known allegorical and nonallegorical texts. One of the reasons I’ve held off on doing that was because it seems like a big project. The time span I have in mind (several centuries), plus the range of styles, genres, national origins, genders, etc. suggest that the test corpus would need to be large (on the order of hundreds of books, say) if it’s not to be dominated by any one author/nation/gender/period/subject/etc. But how much reading and thinking would I have to do to identify, with high confidence, at least 100 major works of allegorical fiction and another 100 of comparable nonallegorical fiction? And would even that be enough? A daunting prospect, though it’s something that I’m probably going to have to do at some point.
But I got an interesting suggestion from Jan Rybicki (who works in authorship attribution, not coincidentally) at DH. Maybe it would suffice, at least preliminarily, to pick a handful of individual authors who wrote both allegorical and nonallegorical works reasonably close together in time, and to look for statistical distinctions between them. Since I’d be dealing with the same author, many of the problems about variations in period, national origin, gender, and so forth would go away, or at least be minimized. I suspect this wouldn’t do very well for finding distinctive keywords, which I imagine would be too closely tied to the specific content of each work (which is a problem that the larger training set is intended to overcome), but it might turn up interesting lower-level phenomena like (just off the top of my head) differences in character n-grams or sentence length. It would take some work to slice and dice the texts in every conceivably relevant statistical way, but I’m going to need to do that anyway and it’s hardly prohibitive.
So that’s one easy, immediate thing to do. In the longer run, what I really want is to see what people in the field have understood to be allegorical and what not, which would have the great advantage, at least as a reference point, of eliminating some of the problems of individual selection bias. One way to do that would be to mine JSTOR, looking, for example, for collocates of “allegor*” or (more ambitiously) trying to do sentiment analysis on actual judgments of allegoricalness. I suspect the latter is out of the question at the moment (as I understand it, the current state of the art is something like determining whether or not customer product reviews are positive or negative, which seems much, much easier than determining whether or not an arbitrary scholarly article considers any one of the several texts it discusses to be allegorical or not). But the former—finding terms that go along with allegory in the professional literature, seeing how the frequency of the term itself and of specific allegorical works and authors changes over (critical) time, and so on—might be both easy and helpful; at the very least, it would be immensely interesting to me. So that’s something to do soon, too, depending on the details of JSTOR access. (JSTOR is one of the partners for the Digging into Data Challenge and they’ve offered limited access to their collection through a program they’re calling “data for research,” so I know they’re amenable to sharing their corpus in at least some circumstances. I was told at THATCamp by Loretta Auvil that SEASR is working with them, too.)
[Incidentally, SEASR is something I’ve been meaning to check out more closely for a long time now. The idea of packaged but flexible data sources, analytics, and visualizations could be really powerful and could save me a ton of time.]
Finally (I had no idea I was going to go on so long), there are a couple of things I should read: Patrick Juola’s “Measuring Linguistic Complexity” (J Quant Ling 5:3 [1998], 206-13)—which might have some pointers on distinguishing complex nonallegorical works from simpler allegorical ones—plus newer work that cites it. And Colin Martindale’s The Clockwork Muse, which has been sitting on my shelf for a while and which was (re)described to me at DH as “brilliant and infuriating and wacky.” Sign me up.