
Gah, this is all nearing completion. Will have a wrap-up of the whole series later tonight; I, for one, await my conclusions with bated breath.
Before I can finish the overall evaluation, here are the results of my last trial, an iteration of the bag-of-tags accuracy tests I’ve been doing, this time with LingPipe. Note, though, that the section below on tagset conversion and this bag-of-tags approach is probably more interesting than the specific LingPipe results (and there are nice summary graphs of the whole shebang down there, too!).
LingPipe Results
For reference, the list of basic tags and a LingPipe-to-MorphAdorner (i.e., Brown-to-NUPOS) translation table are available. Graphs are below, problematic translations from Brown to NUPOS as follow:
- ‘abx’ = pre-quantifier, e.g., “both.” These are usually ‘dt’ in the reference data, but about 30% ‘av’. Adjusted as such in the figures below.
- ‘ap’ = post-determiner, e.g., “many, most, next, last, other, few,” etc. These are complicated; they’re predominantly ‘dt’ (34%), ‘jj’ (22%), ‘nn’ (13%), and ‘nu’ (29%) in the reference data (the other 3% being various other tags). But of course it’s hard to know exactly how much confidence to place in such estimates, absent a line-by-line comparison of all 24,000+ cases. Figures below are nevertheless adjusted according to these percentages.
- ‘ap$’ = possessive post-determiner. There aren’t very many of these, and they’re mostly attached to tokenization errors. Ignored entirely.
- ‘tl’ = words in titles. This is supposed to be a tag-modifying suffix to indicate that the token occurs in a title (see also ‘-hl’ for headlines and ‘-nc’ for citations, but LingPipe uses the ‘tl’ tag alone. Split 50/50 between nouns and punctuation, since those dominate the tokens thus tagged, but this is a kludge.
- ‘to’ = the word “to.” Translated as ‘pc’ = participle, but is also sometimes (~43%) ‘pp’ = preposition in the reference data. Adjusted below.
- LingPipe doesn’t use the ‘fw’ (foreign word) or ‘sy’ (symbol) tags
Data
Table 1: POS frequency in reference data and LingPipe’s output
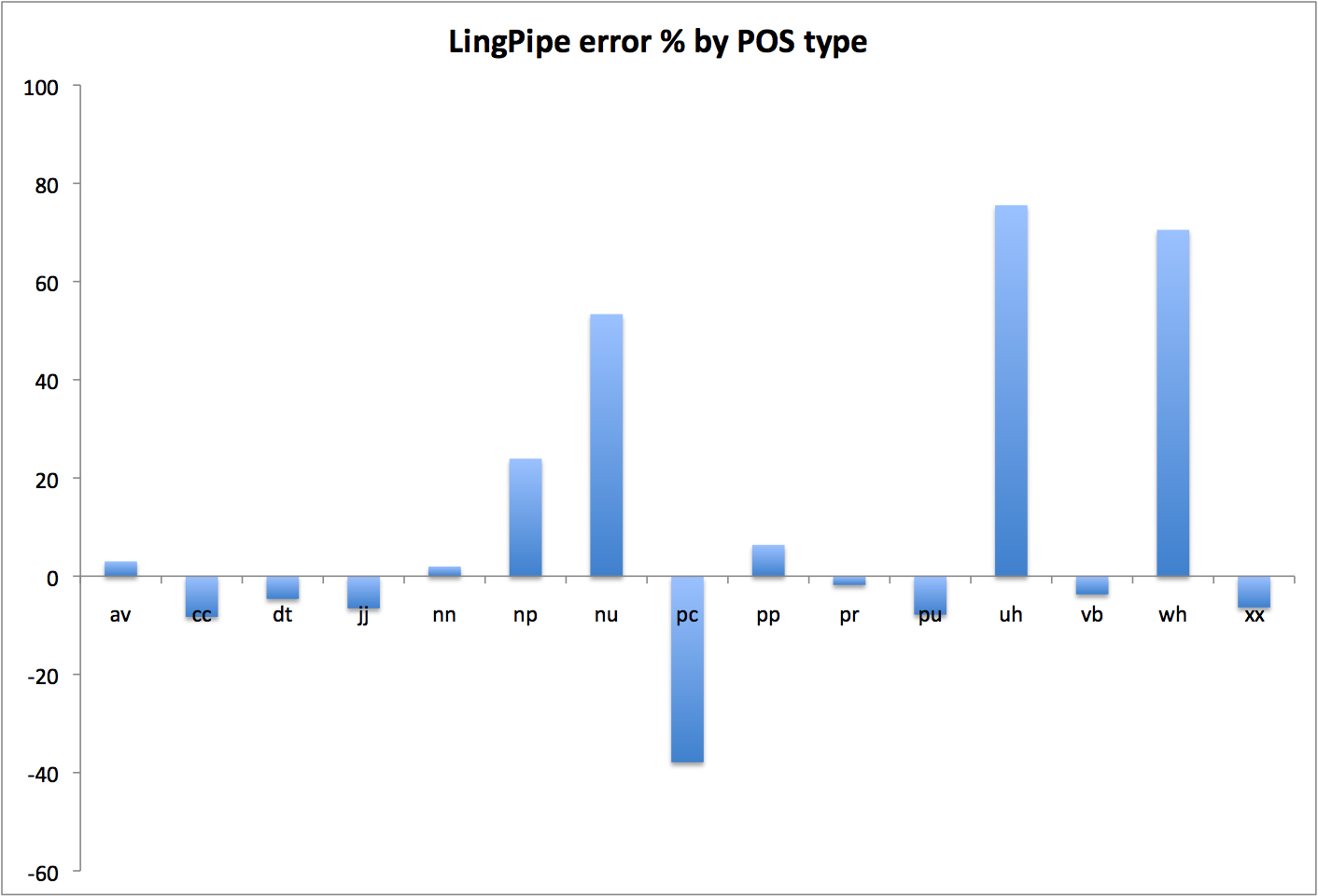
POS Ref Test Ref % Test % Diff Err % av* 213765 228285 5.551 5.718 0.167 3.0 cc 243720 231708 6.329 5.804 -0.525 -8.3 dt* 313671 310143 8.145 7.769 -0.377 -4.6 fw 4117 0.107 -0.107 jj* 210224 203683 5.459 5.102 -0.357 -6.5 nn* 565304 596960 14.680 14.954 0.274 1.9 np 91933 118115 2.387 2.959 0.571 23.9 nu* 24440 38856 0.635 0.973 0.339 53.4 pc* 54518 35098 1.416 0.879 -0.537 -37.9 pp* 323212 356411 8.393 8.928 0.535 6.4 pr 422442 430172 10.970 10.776 -0.194 -1.8 pu* 632749 605152 16.431 15.159 -1.273 -7.7 sy 318 0.008 -0.008 uh 19492 35471 0.506 0.889 0.382 75.5 vb 666095 664957 17.297 16.657 -0.640 -3.7 wh 40162 70998 1.043 1.778 0.736 70.5 xx 24544 23825 0.637 0.597 -0.041 -6.4 zz 167 42272 0.004 1.059 1.055 Tot 3850873 3992106
* Tag counts to which adjustments have been applied (see above)
Legend
POS = Part of speech (see this previous post or this list for explanations)
Ref = Number of occurrences in reference data
Test = Number of occurrences in output
Ref % = Percentage of reference data tagged with this POS
Test % = Percentage of output tagged with this POS
Diff = Difference in percentage points between Ref % and Test %
Err % = Percent error in output frequency relative to reference data
Pictures
And then the graphs (click for large versions).
Figure 1: Percentage point errors in POS frequency relative to reference data
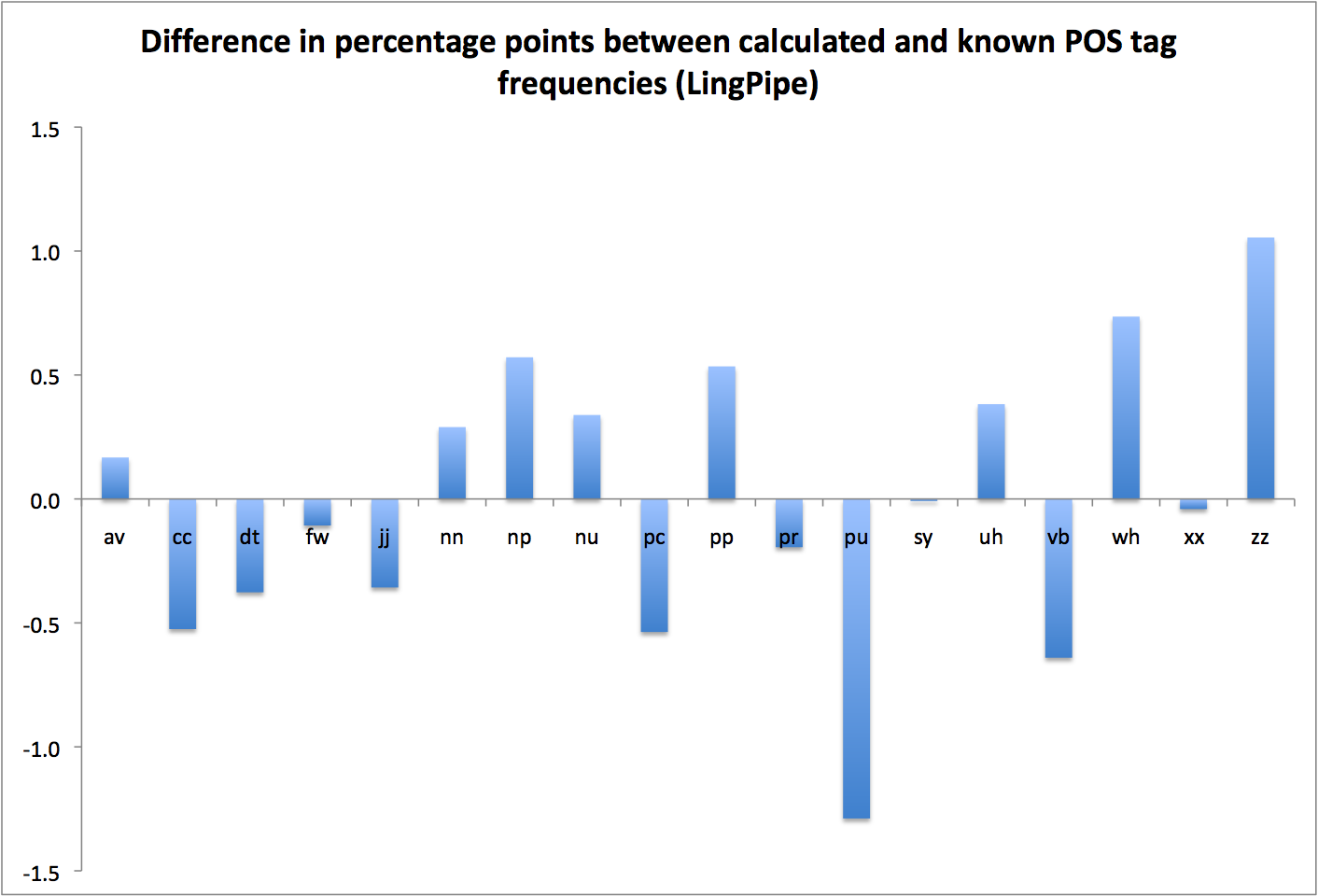
Figure 2: Percent error by POS type relative to reference data
Discussion of LingPipe Results
This is about what we’ve seen with the other taggers that use a base tagset other than NUPOS; it’s a bit better than either Stanford or TreeTagger, a fact that stands out more clearly in the summary comparison graphs below, but there are just too many difficulties converting between any two tagsets to say much more. One could certainly point out some of the obvious features in the present case—LingPipe has a thing for numbers, proper nouns, wh-words, and interjections, plus an aversion to punctuation, verbs, and participles—but I think the only genuinely interesting feature is LingPipe’s willingness to tag things as unknown. I’ve left this out of Figure 2 because it badly skews the scale, but notice in the data above that there are just 167 ‘zz’ tags in the reference corpus, but 42,000+ instances of ‘nil’ (=’zz’) in the LingPipe output.
We didn’t see anything like this with Stanford or TreeTagger, but it might be useful. (Of course, it might also be a mess.) I can imagine situations in which it would be better to know that the tagger has no confidence in its output rather than pushing ahead with garbage results. This is one of the reasons that taggers with the option of producing confidence-based output are (potentially) useful, since they would allow one to isolate borderline cases. LingPipe and TreeTagger have such an option; Stanford and MorphAdorner do not, to the best of my knowledge.
Thoughts on Converting between Tagsets
First, some graphs that collate the results of all the bag-of-tags trials. They’re the same as the ones I’ve been using so far, but now with all the numbers presented together for easier comparison.
As always, click each graph for the full-size image.
Figure 3: Percentage point errors by POS type (Summary)
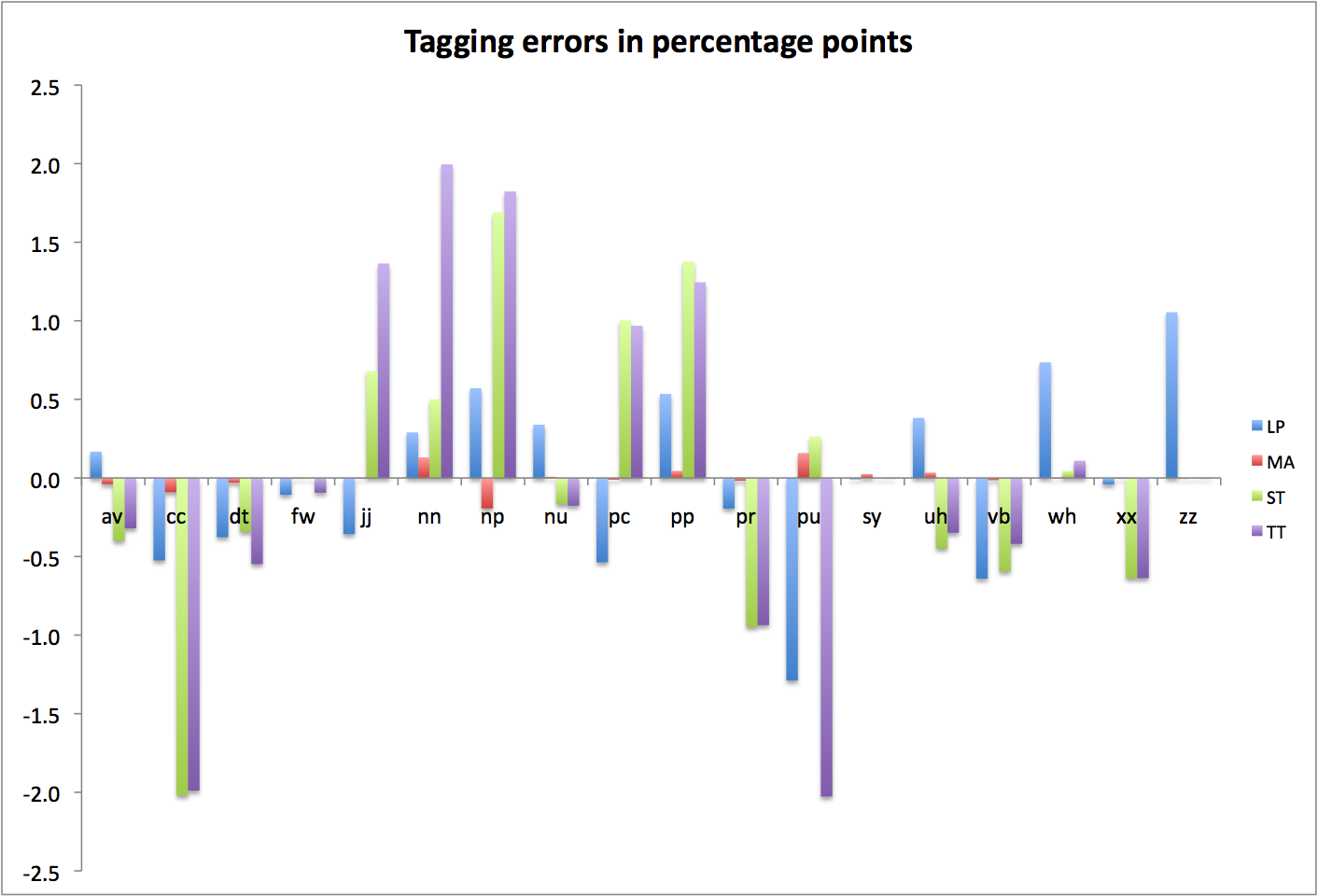
Figure 4: Error % by POS type (Summary)
Note: Y-axis intentionally truncated at +100%.

Figure 5: Weighted error percentages by tagger and POS type (Summary)
This is the one I like best, since it makes plain the relative importance of each POS type; large errors on rare tags generally matter less than modest errors on common tags, though the details will depend on one’s application.

Confirming what you see above: MorphAdorner does well over the reference data, which looks like its own training corpus. (Recall that the MorphAdorner numbers are taken from its cross-validation output and without the benefit of its in-built lexicon, so it’s not just running directly over material it already knows. Apologies for the personification in the preceding sentence.) LingPipe is marginally better than Stanford or TreeTagger (this would be more obvious if the log scale weren’t compressing things in the 1-10% error range), but all three (using different training data and different tagsets) lag MorphAdorner significantly (by an eyeballed order of magnitude, more or less).
So … what have I learned from these attempts to measure accuracy across tagsets? Less than I’d hoped, at least in the direct sense. These trials were motivated by an interest in whether or not taggers trained on non-literary corpora would produce results similar to MorphAdorner’s (which is trained exclusively on literature). The problem was that they all use different tagsets out of the box, and I was somewhere between unwilling and unable to retrain all of them on a common one. My thinking was that I’d be able to smooth out their various quirks by picking a minimal set of parts of speech that they’d all recognize, and then mapping their full tagsets down to this basic one.
The problem is that the various tagsets don’t agree on what should be treated as a special case (wh-words, predeterminers, “to,” etc.), and the special cases don’t map consistently to individual parts of speech. The numbers I’ve presented in each of the recent posts on the topic have tried to apply appropriate statistical fixups, but they’re hacks and (informed) guesses at best. In any case, I think what I’m really seeing is that taggers are reasonably good at reproducing the characteristics of their own training input (which we knew already, based on ~97% cross-validation accuracy). So MorphAdorner does well (generally ~99% accuracy over the reduced tagset, i.e., distinguishing nouns from verbs from other major parts of speech) on data that resembles the stuff on which it was trained; the others do less well on that material, since it differs from their training data not just by genre, but also (and more importantly, I think) by tagset.
(An aside: LingPipe is trained on the Brown corpus, which contains a significant amount of fiction and “belles lettres” [Brown’s term, not mine]. Stanford and TreeTagger use the Penn treebank corpus, i.e., all Wall Street Journal, all the time. So there’s a priori reason to believe that LingPipe should do better than either of those two on literary fiction. I like the Brown tagset better than Penn, too, since it deals more elegantly with negatives, possessives, etc.)
For for the sake of comparison, I looked into running a bag-of-tags evaluation of MorphAdorner over the Brown corpus to see if the accuracy numbers would turn out more like those for the other taggers when faced with “foreign” data. My strong hunch is that they would, but it was going to be more trouble than it was worth to nail it down adequately. Perhaps another time.
Takeaway lessons? Mostly, be careful about direct comparisons of the output of different taggers. If I see somewhere that Irish fiction of the 1830s contains 15% nouns, and know that I’ve seen 17% in British Victorian novels, I probably can’t draw any meaningful conclusions from that fact without access to the underlying texts and/or a lot more information about the tools used. It also means that if I settle on one package, then later change course, I’ll almost certainly need to rerun any previous statistics gathered with the original setup if I’m going to compare them with confidence to new results.
More broadly speaking—and this looks ahead to the overall conclusions in the next post—this all highlights the fact that both tagsets and training data matter a lot. The algorithms used by each of the taggers do differ from one another, even when they use similar techniques, and they make different trade-offs concerning accuracy and speed. But the differences introduced by those underlying algorithmic changes—on the order of 1%, max—are small compared to the ones that result from trying to move between tagsets (and, presumably, between literary and non-literary corpora, though the numbers I’ve presented here don’t throw direct light on that point).
This concludes the bag-of-tags portion of tonight’s program. Stay tuned for the grand finale after the intermission.
See also …
Earlier posts on bag-of-tags accuracy:
