OK, I’m as done as I care to be with the evaluation stage of this tagging business, which has taken the better part of three months of intermittent work. This for a project that I thought would take a week or two. There’s a lesson here, surely, about research work in general, my coding skills in particular, and the (de)merits of being a postdoc.
In short: I’m going to use MorphAdorner for my future work. The good news overall, though, is that several of the other taggers would also be adequate for my needs, if necessary.
Here’s a summary of the considerations that influenced my decision:
Accuracy
This is probably the most important issue, but it’s also the most difficult for me to assess. The underlying algorithms that each tagger implements make a difference, but I’m really not qualified to evaluate the relative merits of hidden Markov models vs. decision trees, for example, nor the quality of the code in each package.
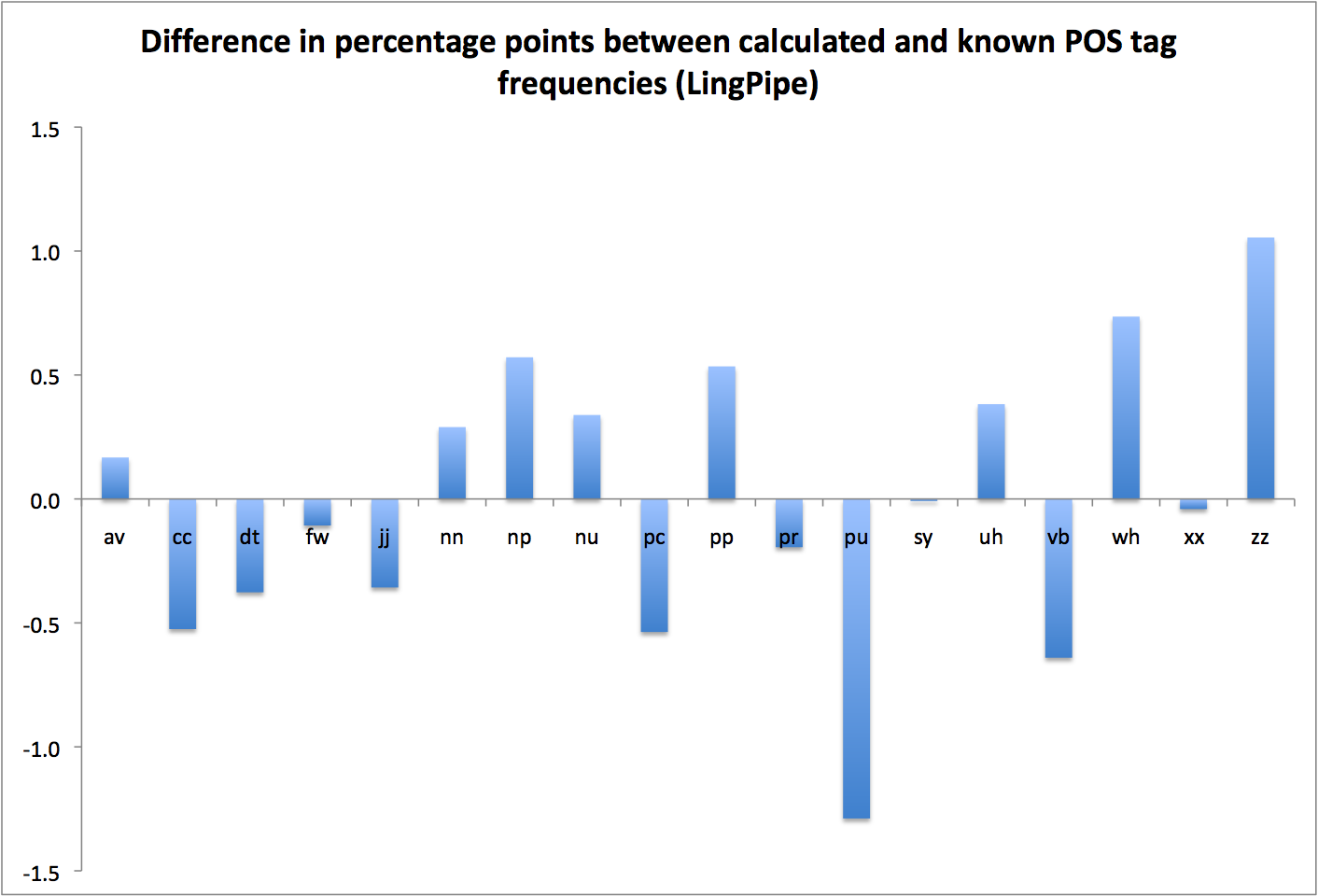
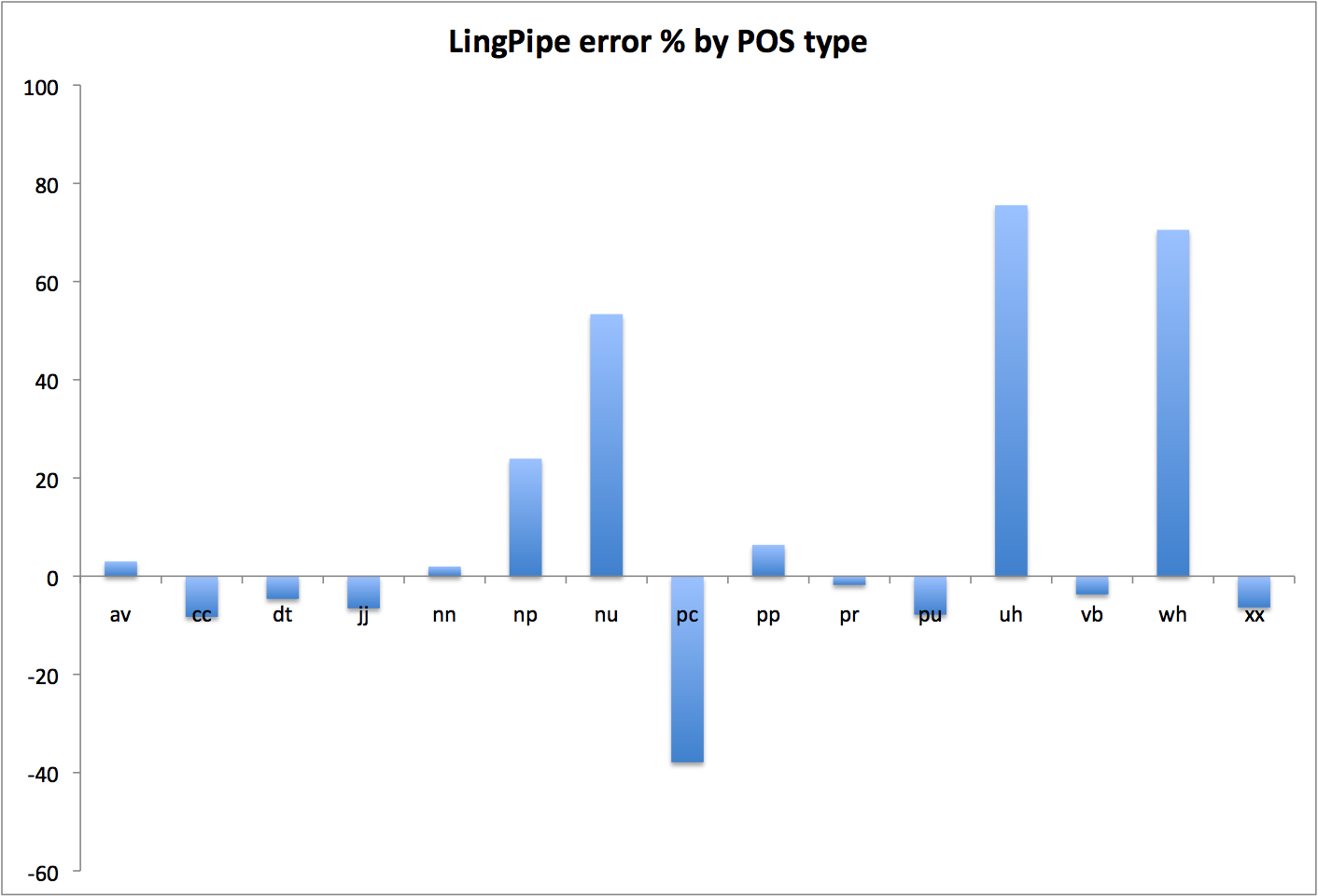
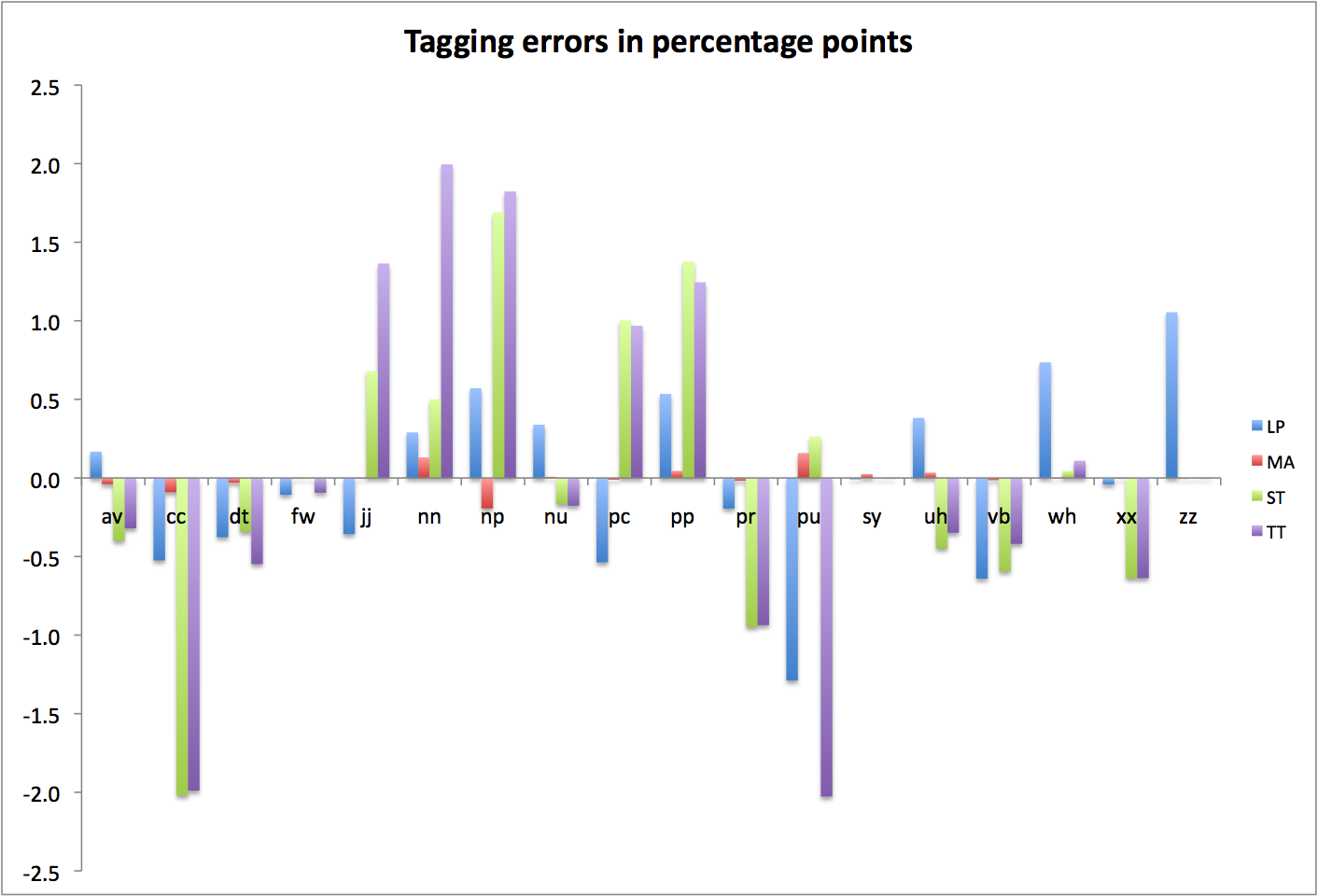
What I do have is cross-validation results, and the deeply inconclusive bag-of-tags trials I’ve described previously. My own cross-validation tests tend to confirm what the projects themselves claim, namely that they’re about 97% accurate on average. Or at least that’s what I saw for MorphAdorner (97.1%) and LingPipe (97.0%); I wasn’t able to retrain the Stanford tagger on my reference data, so I can’t do anything other than accept Stanford’s reported cross-validation numbers on non-literary data, which are 96.9% (for the usably speedy left3words model) and 97.1% (for the very slow bidirectional model). TreeTagger fared very poorly in my cross-validation tests, though there may well have been problems on my end that explain that fact. Still, I’d be reluctant to use it for real work when trained (by me) on something other than its stock (non-literary) corpus; otherwise, TreeTagger’s self-reported cross-validation accuracy is 96.4-96.8%.
As I suggested in my last post, I don’t think the bag-of-tags trials told me much about the relative accuracy of the various taggers, except concerning the larger point that it’s (fundamentally) hard to translate between tagsets. That’s an important thing to know, but I don’t take MorphAdorner’s superiority in those tests as an indication that it’s necessarily more accurate than the others in the general case. I do, however, now understand better MorphAdorner’s performance characteristics on a reduced version of its tagset (it’s about 99% accurate in sum on the larger part-of-speech classes).
There are a priori reasons to think that MorphAdorner might to better out of the box on a literary corpus, since it’s trained on such data and uses a tagset specifically geared to literary-historical usage, but those are issues better addressed separately below; I wouldn’t say that I’ve managed to provide a posteriori support for them here.
Tagset
This matters much more than I imagined at the outset, since it determines not only the level of detail you can investigate, but also the kinds of information that are preserved or lost in a tagger’s output.
Out of the box, then, I think MorphAdorner and NUPOS win for literary work, with LingPipe/Brown a reasonably close second. Stanford and TreeTagger use the significantly smaller Penn tagset, which seems less suitable for my needs. One of the things I learned from the bag-of-tags work was that there isn’t any apparent benefit to working with a reduced tagset from the beginning; there’s no evidence in the trials I’ve run that the increased number of tokens in each of a smaller number of classes in such a tagset provides greater big-picture accuracy as compensation for reduced distributional information. I’d want to run the reverse trial of MorphAdorner over the Brown training corpus to make this claim with more confidence, but for now, that’s how things look.
The good news, of course, is that you can in principle retrain any of the taggers on a reference corpus tagged in any tagset, so you can switch back and forth between them. That is, provided you have access to the appropriate training data. Now, I do have access to MorphAdorner’s training data, but I don’t have the right to redistribute it, and I’m not sure what would be involved in doing so, were it necessary. And there’s a certain amount of work and computational horsepower involved in performing the retraining. Assuming I want to use NUPOS (and I do; see Martin Mueller’s NUPOS primer/rationale), MorphAdorner is the easiest way to get it.
Training Data
MorphAdorner is trained on a strictly literary corpus, both British and American, that spans the early modern period through the twentieth century. LingPipe uses the Brown corpus via NLTK, which has a good deal of fiction, but is certainly not exclusively literary. Stanford and TreeTagger use the Wall Street Journal (Penn treebank corpus). If each of the training corpora has been tagged with equal accuracy, one would expect MorphAdorner’s corpus to be best suited to arbitrary literary work, though it has the drawback of not being freely redistributable. I’m not sure if this is likely ever to change, as I’m told that although the works themselves are long out of copyright, the texts were originally derived at least in part from commercial sources like Chadwyck-Healey. It’s something to be aware of, but so long as the compiled model can be passed along (and it obviously can be, since it’s included with the base distribution), it will be possible for others to replicate my work. I’m not sure what, if any, issues I’d encounter if I were to reuse the training data with another tagger, though I don’t see why they’d be much different from those involving MorphAdorner itself.
MorphAdorner’s tokenizer and lemmatizer are also intended to deal accurately and efficiently with the vagaries of early modern orthography, which is certainly a plus.
In any case, one of the advantages of using MorphAdorner is that I don’t have to think about this stuff, nor do I have to work on retraining another tagger, nor do I have to worry about trying to pick up and replicate any improvements to, or refinements of, MorphAdorner’s training data that might happen down the road.
Speed
I didn’t imagine at the outset that speed would fall so far down my list of considerations, but I think this is the right place for it in my own usage scenario. As I mentioned in an earlier post, speed is a qualitative threshold issue for me. Quoting that post:
Faster is better, but the question isn’t really “which tagger is fastest?” but “is it fast enough to do x” or “how can I use this tagger, given its speed?” I think there are three potentially relevant thresholds:
- As a practical matter, can I run it once over the entire corpus?
- Could I retag the corpus more or less on whim, if it were necessary or useful?
- Could I retag the corpus in real time, on demand, if there turned out to be a reason to do so?
The first question is the most important one: I definitely have to be able to tag the entire corpus once. The others would be nice, especially #2, but I don’t yet have a compelling reason to require them.
To recap my earlier conclusions, TreeTagger, LingPipe, and MorphAdorner are all fast enough to meet thresholds 1 and 2. Stanford, using the (slightly less accurate) left3words model, meets threshold 1 (tag everything once) and might meet number 2 (tag it again) in a pinch. Stanford bidirectional would be a real stretch to run over a large corpus even once on moderate (read: affordable and accessible to a humanist) hardware. None of the taggers is fast enough on my hardware for full on-demand work, though it’s worth recalling that I made no real attempts to optimize for speed (Bob Carpenter at Alias-i reports 100x speedups of LingPipe are possible with some tweaking). But this on-demand business is a theoretical rather than an immediately practical issue for my work, so I don’t attach much weight to it.
License, Source Code, and Cost
Here it makes sense to break things down case by case:
MorphAdorner: Not yet generally available, but forthcoming when Phil Burns finishes the documentation, probably mid-late February of this year (2009). To be released under a modified NCSA license, freely redistributable with attribution. The same can’t be said of the raw training data, I think, but the compiled models will be included. No cost, all source code available. Under active development.
LingPipe: The only commercial offering of the bunch. Open source and free to use, provided you make all tagged output available in turn. That wouldn’t be a problem for me at the moment, when I’m looking to work with freely available texts (Gutenberg, etc.), but could be a limitation later if/when I use copyrighted corpora. Exceptions to the redistribution requirement are available for sale from Alias-i; they can be modest to pricey in the context of grant-challenged academic humanities, though Bob has suggested that there may be flexibility in their licensing for academics. In any case, I don’t doubt that I could make it work in my own case, but I have at least minor reservations about the impact of using commercial tools on the subsequent adoption of my methods. The ideal case would be for anyone who’s interested to pick up my toolset with the fewest possible encumbrances. That’s not to say there aren’t issues with the other packages’ licensing terms (and probably more importantly with copyright issues involving my working corpora), nor that I object to Alias-i’s business model (which I think is an eminently reasonable compromise between openness and the need to feed themselves), but it’s a consideration. Under very active development, and with outstanding support from the lead developer (the aforementioned Bob Carpenter).
Stanford: Like the other academic packages, open source and free software. Licensed under GPL2. Under active development.
TreeTagger: Distributed free for “research, teaching, and evaluation purposes.” No right to redistribute. No source code available and not under active development, as far as I can tell. [Update: Helmut Schmid writes to tell me that TreeTagger is indeed still under development.]
Other Considerations
There were a few other minor concerns and thoughts.
Threadsafeness can be an issue for the Java-based taggers (that is, all but TreeTagger). LingPipe is threadsafe. Stanford is not. MorphAdorner, I don’t know. This isn’t an immediate concern, since I have enough memory to throw at two separate JVM instances and only two cores to work with, but it would be a nice thing to have in the future.
Input/output encodings and formats. All three of the Java-based taggers can handle Unicode text (which is good), and they can take input data in either plain text or XML format. MorphAdorner and Stanford by default give you back out the same format you put in; LingPipe (again, by default) gives you XML output either way. Doesn’t make much difference to me, and it’s easy to write a simple output filter for any of the packages (TreeTagger possibly excepted) that gives you what you want.
Finally, Bob suggests having a look at NLTK, which I mentioned in an earlier post but didn’t really do anything with. Certainly something to keep in mind for the future, especially as it has a kind of “welcome to NLP work, please allow me to show you around and make things easier for you” vibe. It’s Python-based and GPL2 licensed. Will investigate as time allows.
And that, finally, is that. Back to proper literary work for a bit—polishing off the Coetzee article and talk I mentioned a while ago–then to book manuscript revisions. But the computational work will continue through the spring and summer. With results, eventually, I swear!